Publications
2026
- ECCV 2026
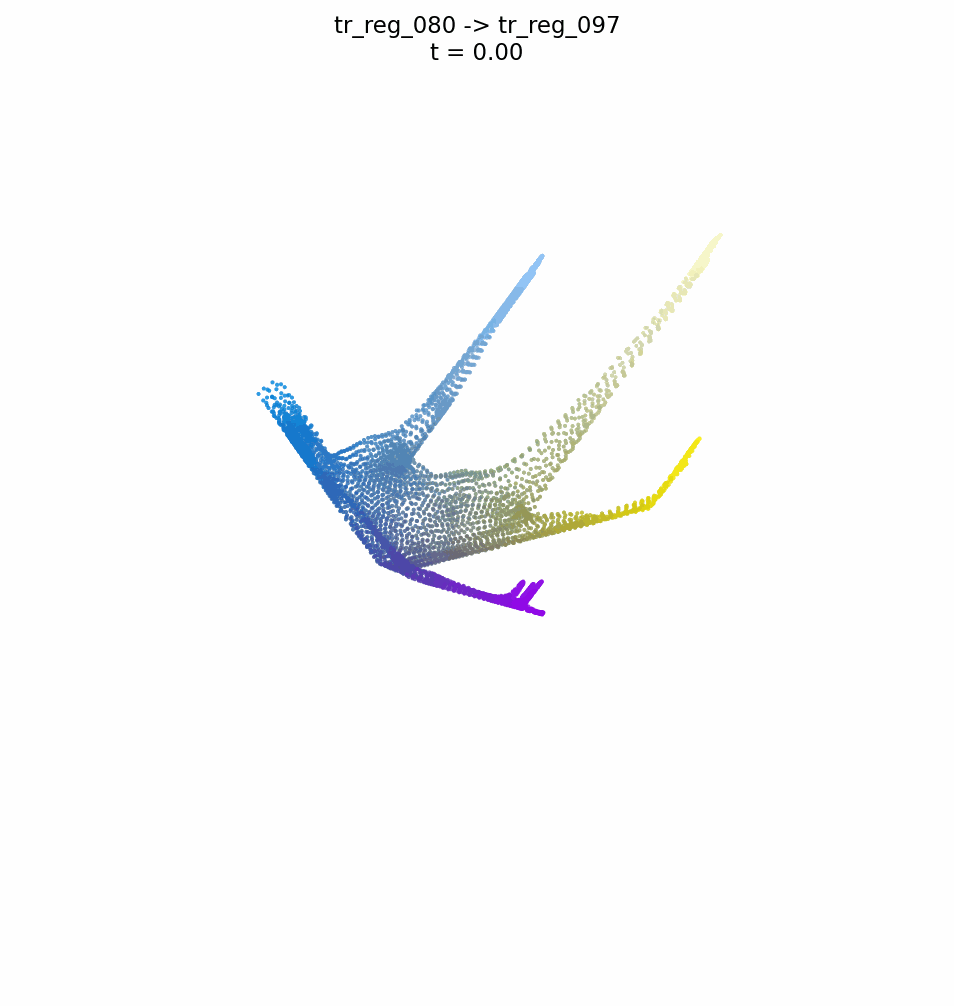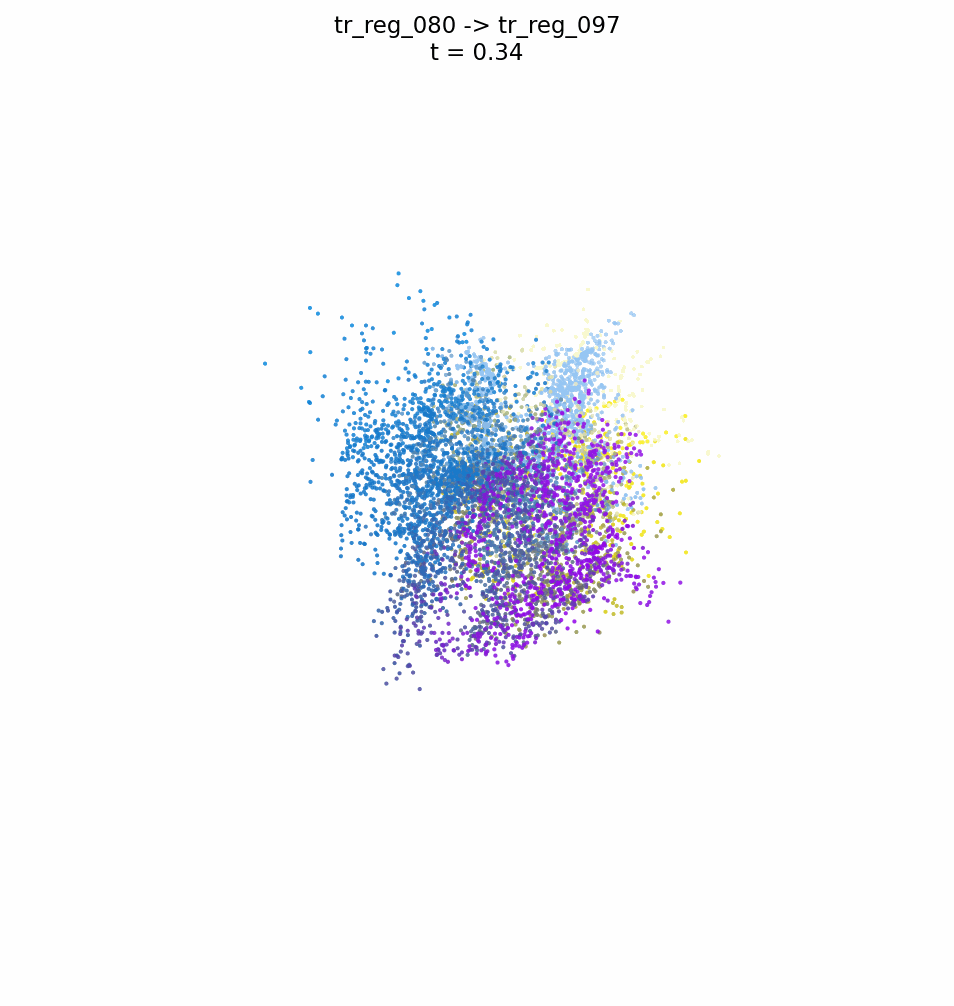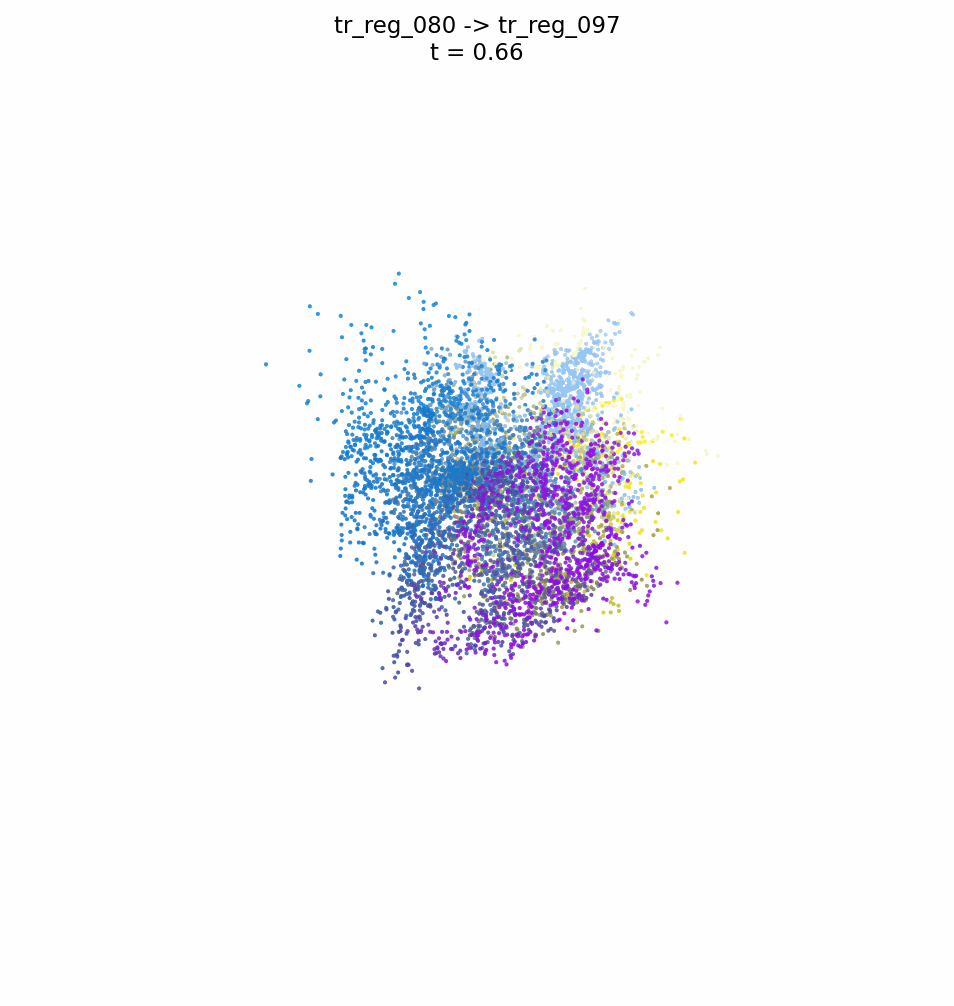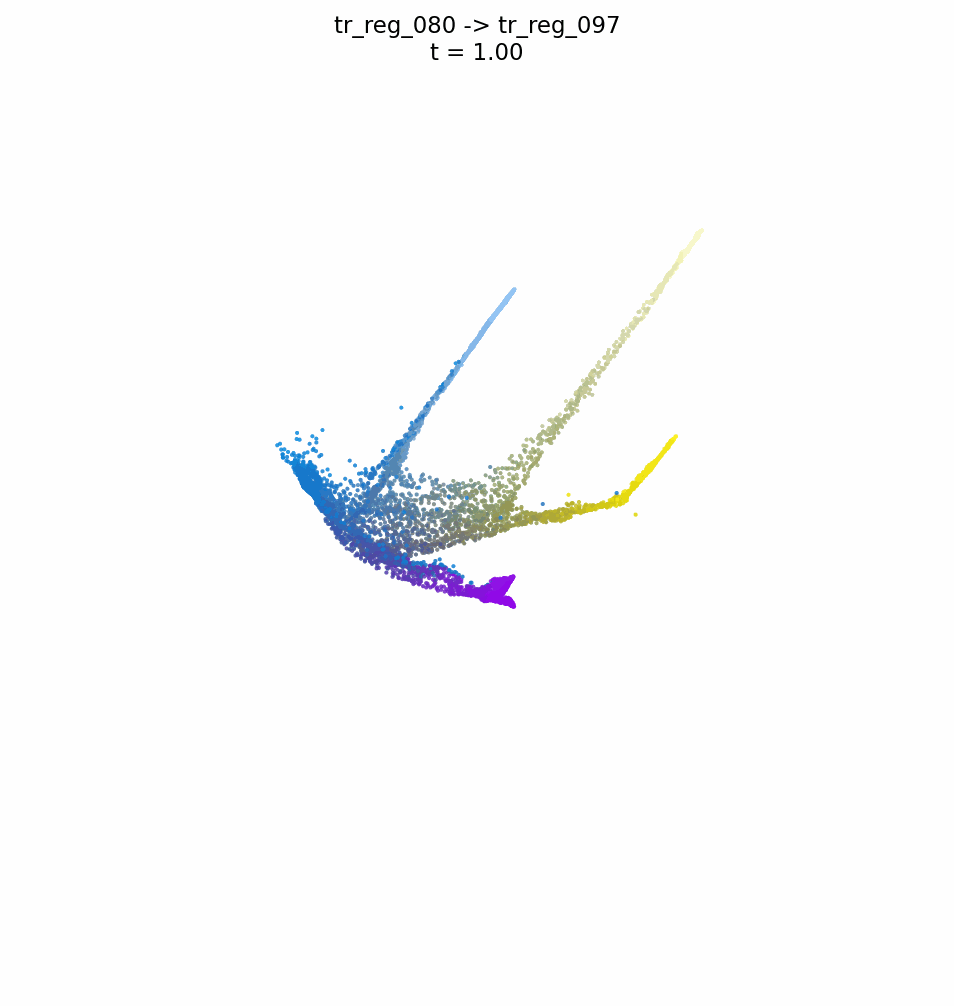 FUSE: A Flow-based Mapping Between ShapesLorenzo Olearo, Giulio Viganò, Daniele Baieri, Filippo Maggioli, and Simone Melzi2026
FUSE: A Flow-based Mapping Between ShapesLorenzo Olearo, Giulio Viganò, Daniele Baieri, Filippo Maggioli, and Simone Melzi2026We introduce a novel neural representation for maps between 3D shapes based on flow-matching models, which is computationally efficient and supports cross-representation shape matching without large-scale training or data-driven procedures. 3D shapes are represented as the probability distribution induced by a continuous and invertible flow mapping from a fixed anchor distribution. Given a source and a target shape, the composition of the inverse flow (source to anchor) with the forward flow (anchor to target), we continuously map points between the two surfaces. By encoding the shapes with a pointwise task-tailored embedding, this construction provides an invertible and modality-agnostic representation of maps between shapes across point clouds, meshes, signed distance fields (SDFs), and volumetric data. The resulting representation consistently achieves high coverage and accuracy across diverse benchmarks and challenging settings in shape matching. Beyond shape matching, our framework shows promising results in other tasks, including UV mapping and registration of raw point cloud scans of human bodies.
- DAI - Q1
 Blending Concepts with Text-to-Image Diffusion ModelsLorenzo Olearo, Giorgio Longari, Alessandro Raganato, Rafael Peñaloza, and Simone Melzi2026
Blending Concepts with Text-to-Image Diffusion ModelsLorenzo Olearo, Giorgio Longari, Alessandro Raganato, Rafael Peñaloza, and Simone Melzi2026Diffusion models have dramatically advanced text-to-image generation in recent years, translating abstract concepts into high-fidelity images with remarkable ease. In this work, we examine whether they can also blend distinct concepts, ranging from concrete objects to intangible ideas, into coherent new visual entities under a zero-shot framework. Specifically, concept blending merges the key attributes of multiple concepts (expressed as textual prompts) into a single, novel image that captures the essence of each concept. We investigate four blending methods, each exploiting different aspects of the diffusion pipeline (e.g., prompt scheduling, embedding interpolation, or layer-wise conditioning). Through systematic experimentation across diverse concept categories, such as merging concrete concepts, synthesizing compound words, transferring artistic styles, and blending architectural landmarks, we show that modern diffusion models indeed exhibit creative blending capabilities without further training or fine-tuning. Our extensive user study, involving 100 participants, reveals that no single approach dominates in all scenarios: each blending technique excels under certain conditions, with factors like prompt ordering, conceptual distance, and random seed affecting the outcome. These findings highlight the remarkable compositional potential of diffusion models while exposing their sensitivity to seemingly minor input variations.


2024
- WorkshopHow to Blend Concepts in Diffusion ModelsLorenzo Olearo, Giorgio Longari, Simone Melzi, Alessandro Raganato, and Rafael PeñalozaarXiv preprint arXiv:2407.14280, 2024
For the last decade, there has been a push to use multi-dimensional (latent) spaces to represent concepts; and yet how to manipulate these concepts or reason with them remains largely unclear. Some recent methods exploit multiple latent representations and their connection, making this research question even more entangled. Our goal is to understand how operations in the latent space affect the underlying concepts. To that end, we explore the task of concept blending through diffusion models. Diffusion models are based on a connection between a latent representation of textual prompts and a latent space that enables image reconstruction and generation. This task allows us to try different text-based combination strategies, and evaluate easily through a visual analysis. Our conclusion is that concept blending through space manipulation is possible, although the best strategy depends on the context of the blend.
- JournalFacing multidimensional poverty in older adults: An artificial intelligence approach that reveals the variable relevanceLorenzo Olearo, Fabio D’Adda, Enza Messina, Marco Cremaschi, Stefania Bandini, and Francesca GaspariniIntelligenza Artificiale, 2024
Despite the rapid development in very recent years of Artificial Intelligence models to predict poverty risk, this problem still remains an unsolved open challenge, especially from a multidimensional perspective. One of the main challenges is related to the scarcity of labelled and high-quality data for training models coupled with the lack of a general reference model to build good predictors. This results in the proposal of a variety of approaches tailored to specific contexts. This paper presents our proposal to address multidimensional poverty prediction, starting from an unlabelled dataset. We focus on the case of a fragile population, the older adults; our approach is highly flexible and can be easily adapted to various scenarios. Firstly, starting from expert knowledge, we apply a stochastic method for estimating the probability of an individual being poor, and we use this probability to identify three levels of risk. Then, we train an XGBoost classification model and exploit its tree structure to define a ranking of feature relevance. This information is used to create a new set of aggregated features representative of different poverty dimensions. An explainable novel Naive Bayes model is then trained for predicting individuals’ deprivation level in our particular domain. The capacity to identify which variables are predominantly associated with poverty among older adults offers valuable insights for policymakers and decision-makers to address poverty effectively.
2022
- ConferenceA comparison of temporal aggregators for speaker verificationFlavio Piccoli, Lorenzo Olearo, and Simone BiancoIn 2022 IEEE 12th International Conference on Consumer Electronics (ICCE-Berlin) , 2022
Speaker verification is the task of examining a speech signal to authenticate the claimed identity of a speaker as true or false. In order to deal with utterances having different lengths, and to accumulate information along the time dimension, different temporal aggregators have been proposed inside speaker verification pipelines. In this paper we investigate the behavior of five different temporal aggregators in the state of art, namely Temporal Average Pooling (TAP), Global Statistical Pooling (GSP), Self-Attentive Pooling (SAP), Attentive Statistical Pooling (ASP), and Vector of Locally Aggregated Descriptors (VLAD) at varying lengths of the two utterances. Starting from a speaker verification method in the state of the art, the experimental results on the VoxCeleb2 dataset show that there is a sweet spot for utterance length where speaker verification performance is higher independently from the temporal aggregator used.